Thomas Dinsmore's Blog
About Me
Category:
News Analysis
February 21, 2018
Notes on a Watson FAIL
February 14, 2017
Spark is the Future of Analytics
January 16, 2017
The Year in Machine Learning (Part Four)
January 9, 2017
The Year in Machine Learning (Part Three)
October 3, 2016
How to Steal a Predictive Model
September 27, 2016
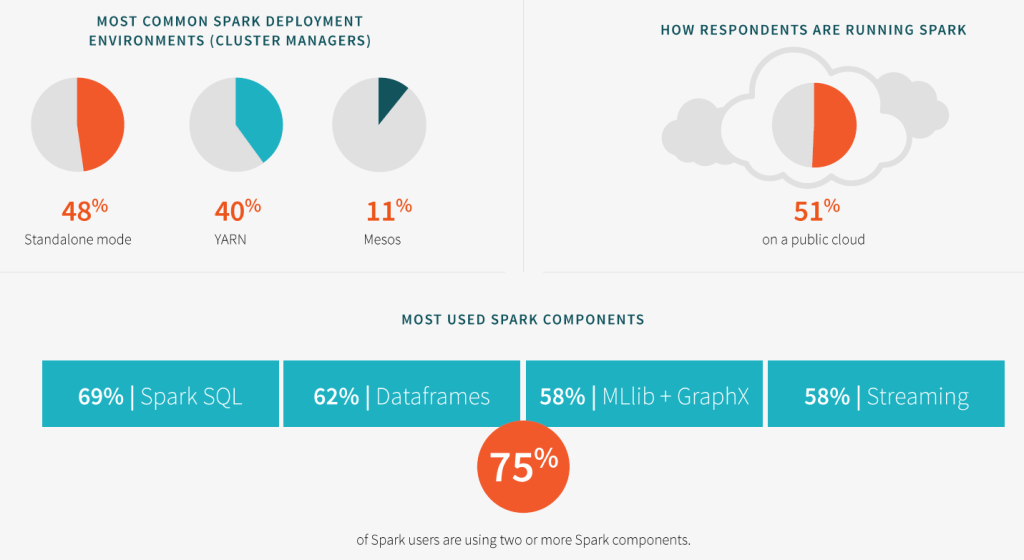
Databricks Releases Spark Survey
July 11, 2016
Databricks’ 2016 Spark Survey
May 5, 2016
Teradata Reports Loss, Fires CEO
February 22, 2016
Gartner’s 2016 MQ for Advanced Analytics Platforms
February 15, 2016
Teradata’s Dim Prospects
1
2
3
4
Older Posts
Privacy & Cookies: This site uses cookies. By continuing to use this website, you agree to their use.
To find out more, including how to control cookies, see here:
Cookie Policy
Subscribe
Subscribed
Thomas Dinsmore's Blog
Join 1,037 other subscribers
Sign me up
Already have a WordPress.com account?
Log in now.
Thomas Dinsmore's Blog
Subscribe
Subscribed
Sign up
Log in
Report this content
View site in Reader
Manage subscriptions
Collapse this bar