Databricks is running a short survey to understand the needs of Apache Spark users. If you haven’t taken the survey yet, do so today.
For results of the 2015 survey, look here. Last year’s survey produced a number of interesting findings; here’s what I wrote back in September when Databricks released its report:
=====
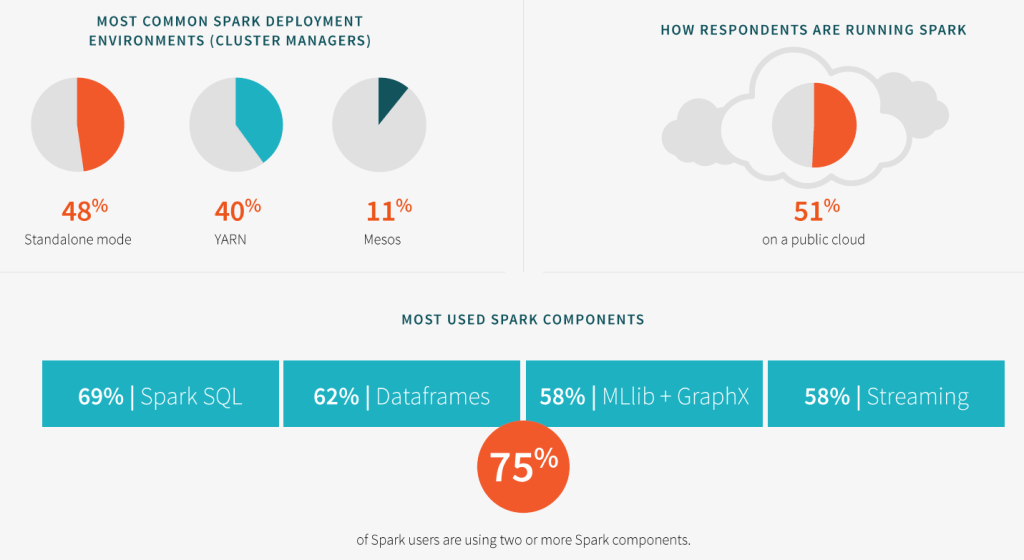
Databricks released results of its 2015 Spark Survey, available here (registration required); an infographic is here. The report is an informative mashup of survey findings, plus other information, such as the headcount from Spark Summits. (Spoiler: it’s increasing.) On the Databricks blog, Matei Zaharia, Patrick Wendell and Denny Lee summarize key points. See additional analysis here, here, here, here, here, here, here and here.
Analysts, loving controversy, note that Spark users slightly prefer standalone configurations over Spark-on-YARN (e.g. co-located in Hadoop). Andrew Oliver, for example, commenting on Cloudera’s One Platform announcement earlier this month, argues that Databricks is actively marketing against Spark-on-YARN, citing results of this survey. But if you compare these results to the Typesafe/Databricks Spark survey published in January, you will note that respondents to the 2015 survey are slightly less likely to run Spark in a standalone cluster this year compared to last year.
Other analysts, like Tony Baer, note that 11% of respondents run Spark on Mesos, hinting darkly that since the AMPLab team developed both Spark and Mesos, there must be some sort of conspiracy against Hadoop. But in the earlier survey, 26% of respondents said they run on Mesos, so if someone is organizing a secret cabal to compete against Spark-on-YARN, it’s not working out too well.
The biggest news in the survey is the rapid growth of users who use the Python API, from 22% to 58%, and the corresponding decline among those who use Scala or Java. The SQL and R interfaces are too new to compare to the previous survey, but it’s worth noting that in 2015 more respondents use the SQL interface than the Java interface.




Leave a comment