Which is better for analytics, SAS or R? One frequently sees discussions on this topic in social media; for examples, see here, here, here, here, here and here. Like many debates in social media, the degree of conviction is often inverse to the quantity of information, and these discussions often produce more heat than light.
The question is serious. Many organizations with a large investment in SAS are actively considering whether to adopt R, either to supplement SAS or to replace it altogether. The trend is especially marked in the analytic services industry, which is particularly sensitive to SAS licensing costs and restrictive conditions.
In this post, I will recap some common myths about SAS and R. In a follow-up post, I will summarize the pros and cons of each as an analytics platform.
Myths About SAS and R
Advocates for SAS and R often support their positions with beliefs that are little more than urban legends; as such, they are not good reasons to choose SAS over R or vice-versa. Let’s review six of these myths.
(1) Regulatory agencies require applicants to use SAS.
This claim is often cited in the context of submissions to the Food and Drug Administration (FDA), apparently by those who have never read the FDA’s regulations governing submissions. The FDA accepts submissions in a range of formats including SAS Transport Files (which an R user can create using the StatTransfer utility.) Nowhere in its regulations does the FDA mandate what software should be used to produce the analysis; like most government agencies, the FDA is legally required to support standards that do not favor single vendors.
Pharmaceutical firms tend to rely heavily on SAS because they trust the software, and not due to any FDA mandate. Among its users, SAS has a deservedly strong reputation for quality; it is a mature product and its statistical techniques are mature, well-tested and completely documented. In short, the software works, which means there is very little incentive for an established user to experiment with something else, just to save on licensing fees.
That trust in SAS isn’t a permanent state of affairs. R is gradually making inroads in the life sciences community; it has already largely displaced SAS in the academic world. Like many other regulatory bodies, the FDA itself uses open source R together with SAS.
(2) R is better than SAS because it is object oriented.
This belief is wrong on two counts: (1) it assumes that object-oriented languages are best for all use cases; and (2) it further assumes that SAS offers no object-oriented capability.
Object-oriented languages are more efficient and easier to use for many analysis tasks. In real-world analytics, however, we often work with messy and complex data; a cursor-based language like the SAS DATA Step offers the user a great deal of flexibility, which is why it is so widely used. Anyone who has ever attempted to translate SAS “first and last” processing into an object-oriented language understands this point. (Yes, it can be done; but it requires a high-level of expertise in the OOL to do it).
In Release 9.3, SAS introduced DS2, an object-oriented language with a defined migration path from SAS DATA Step programming. Hence, for those tasks where object-oriented programming is desirable, DS2 meets this need for the SAS user. (DS2 is included with Base SAS).
(3) You never know what’s inside open source software like R.
Since R is an open programming environment, anyone can develop a package and contribute it to the project. Commercial software vendors like to plant FUD about open source software by suggesting that contributors may be amateurs or worse — in contrast to the “professional” engineering of commercial software.
One of the key virtues of open source software is that you do know what’s inside it because — unlike commercial software — you can inspect the source code. With commercial software, you must have faith in the vendor’s integrity, technical support and willingness to stand by its warranty. For open source software, there is no warranty nor is one required; the code speaks for itself.
When a contributor publishes an enhancement to R, a large community of users evaluates and tests the new feature. This “crowdsourced” testing quickly flags and logs issues with software syntax and semantics, and logged issues are available for anyone to see.
Commercial software vendors like SAS have professional testing and QA departments, but since testing is expensive there is considerable pressure to minimize the expense. Under the pressure of Marketing and Sales deadlines, systematic testing is often the first task to be cut. Bismarck once said that nobody should witness how laws or sausages are made; the same is true for commercial software.
SAS does not disclose the headcount it commits to software testing and QA, but given the size of the R user base, it’s fair to say that the number of people who test and evaluate each R release is far greater than the number of people who evaluate each SAS release.
(4) R is better than SAS because it has thousands of packages.
This is like arguing that Wal-Mart is a better store than Brooks Brothers because it carries more items. Wal-Mart’s breadth of product makes it a great shopping destination for many shoppers, but a Brooks Brothers shopper appreciates the store’s focus on a certain look and personalized service.
By analogy, R’s cornucopia of functionality is both a feature and a bug. Yes, there is a package in R to support every conceivable analytic need; in many cases, there is more than one package. As of this writing, there are 486 packages that support linear regression, which is great unless you only need one and don’t want to sift through 486.
Of course, actual R users don’t check every package to find what they need; they settle on a few trusted packages based on actual experience, word-of-mouth, books, periodicals or other sources of information. In practice, relatively few R packages are actually used; the graph below shows package downloads from RStudio’s popular CRAN mirror in September 2014.
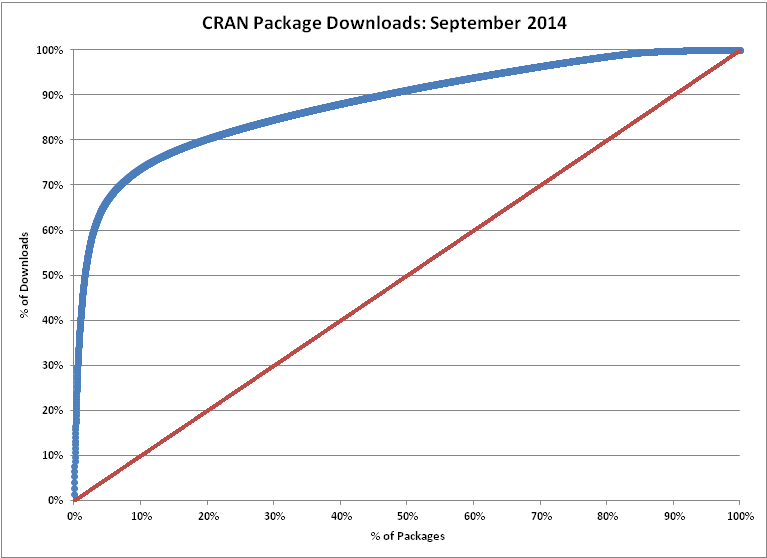
(For the record, the ten most downloaded packages from RStudio’s CRAN mirror in September 2014 were Rcpp, plyr, ggplot2, stringr, digest, reshape2, RColorBrewer, labeling, colorspace and scales.)
For actual users, the relevant measure isn’t the total number of features supported in SAS and R; it’s how those features align with user needs.
N.B. — Some readers may quibble with my use of statistics from a single CRAN mirror as representative of the R community at large. It’s a fair point — there are at least 105 public CRAN mirror sites worldwide — but given RStudio’s strong market presence it’s a reasonable proxy.
(5) Switching from SAS to R is expensive because you have to rewrite all of your code.
It’s true that when switching from SAS to R you have to rewrite programs that you want to keep; there is no engine that will translate SAS code to R code. However, SAS users tend to overestimate the effort and cost to accomplish this task.
Analytic teams that have used SAS for some years typically accumulate a large stock of programs and data; much of this accumulation, however, is junk that will never be re-used. Keep in mind that analytic users don’t work the same way as software developers in IT or a software engineering organization. Production developers tend to work in a collaborative environment that ensures consistent, reliable and stable results. Analytic users, on the other hand, tend to work individually on ad hoc analysis projects; they are often inconsistently trained in software best practices.
When SAS users are pressed to evaluate a library of existing programs and identify the “keepers”, they rarely identify more than 10-20% of the existing library. Hence, the actual effort and expense of program conversion should not be a barrier for most organizations if there is a compelling business case to switch.
It’s also worth noting that sticking with SAS does not free the organization from the cost of code migration, as SAS customers discovered when SAS 9 was released.
The real cost of switching from SAS to R is measured in human capital — in the costs of retraining skilled professionals. For many organizations, this is a deal-breaker at present; but as more R-savvy analysts enter the workforce, the costs of switching will decline.
(6) R is a good choice when working with Big Data.
When working with Big Data, neither “legacy” SAS nor open source R is a good choice, for different reasons.
Open source R runs in memory on a single machine; it can work with data up to available memory, then fails. It is possible to run R in a Hadoop cluster or as table functions inside MPP databases. However, since R runs independently on each node, this is useful only for embarrassingly parallel tasks; for most advanced analytics tasks, you will need to invoke a distributed analytics engine. There are a number of distributed engines you can invoke from R, including H2O, ScaleR and Skytree, but at this point R is simply a client and the actual work is done by the distributed engine.
“Legacy” SAS uses file-swapping to handle out-of-memory problems, but at great cost to performance; when a data set is too large to load into memory, “legacy” SAS slows to a crawl. Through SAS/ACCESS, SAS supports the ability to pass through SQL operations to MPP databases and HiveQL, MapReduce and Pig to Hadoop; however, as is the case with R, “legacy” SAS simply functions as a client and the work is done in the database or Hadoop. The user can accomplish the same tasks using any SQL or Hadoop interface.
To its credit, SAS also offers distributed in-memory software that runs inside Hadoop (the SAS High-Performance Analytics suite and SAS In-Memory Statistics for Hadoop). Of course, these products do not replicate “legacy” SAS; they are entirely new products that support a subset of “legacy” SAS functionality at extra cost. Some migration may be required, since they run DS2 but not the traditional SAS DATA Step. (I cite these points not to denigrate the new SAS software, which appears to be well designed and implemented, but to highlight the discontinuity for SAS users between the “legacy” product and the scalable High Performance products.)
If your organization works with Big Data, your primary focus should be on choosing the right scalable analytics platform, with secondary emphasis on the client or API used to invoke it.




Leave a comment