
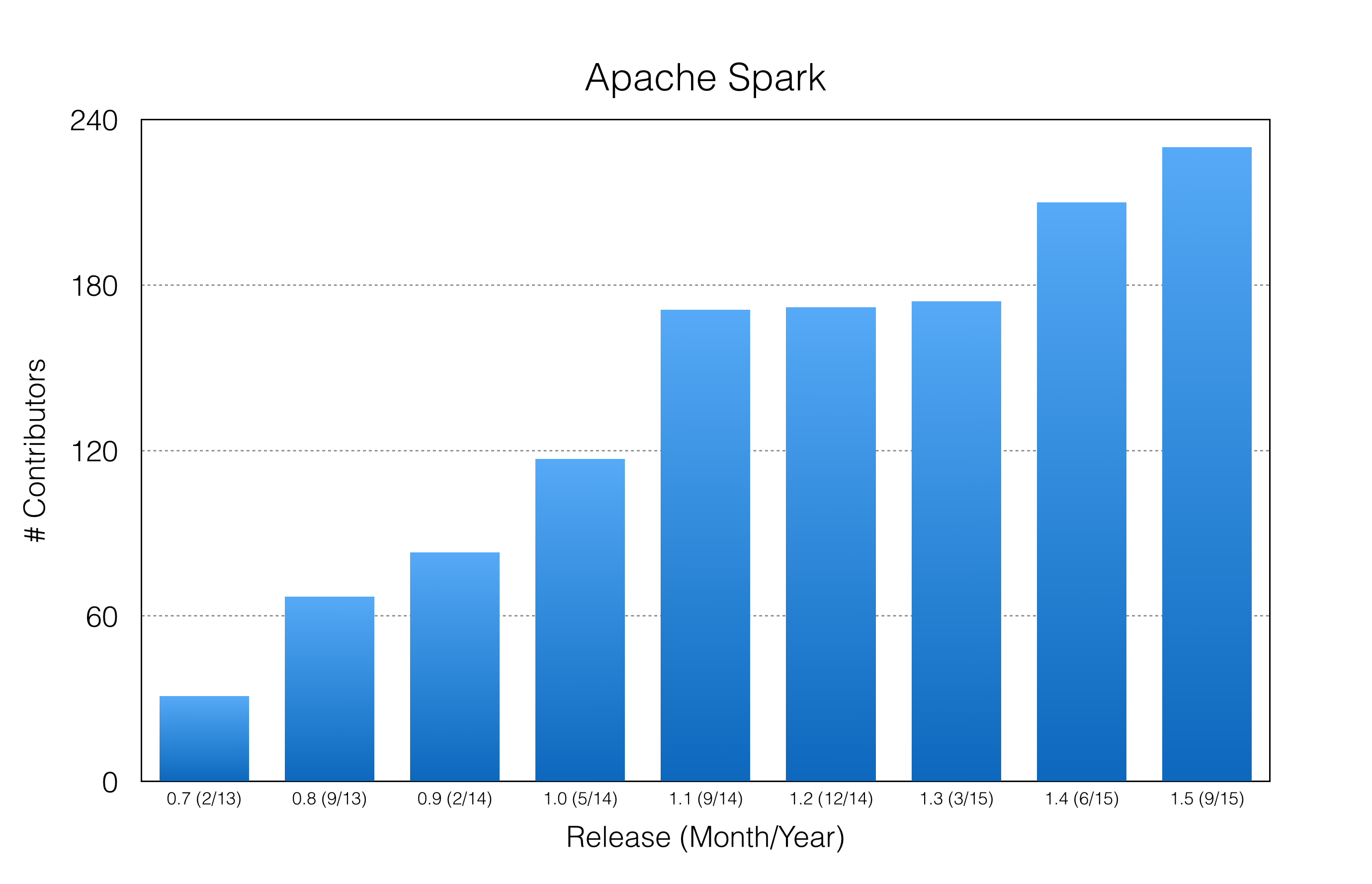
On September 9, the Spark team announced availability of Release 1.5. (Release notes here.) 230 developers contributed more than 1,400 commits, the largest release to date. Spark continues to expand its contributor base, the best measure of health for an open source project.
On the Databricks blog, Reynold Xin and Patrick Wendell summarize the key new bits: Some highlights:
- Project Tungsten, a set of major changes to Spark’s internal architecture will be on by default. Spark 1.5 includes binary processing and a new code generation framework, with more than 100 built-in functions for common tasks.
- Other performance enhancements include improved Parquet support (with predicate push-down and a faster metadata lookup path), and improved joins.
- Usability enhancements include visualization of the SQL and DataFrame query plans in the web UI; the ability to connect to multiple versions of Hive metastores and the ability to read several Parquet variants.
- Spark Streaming adds stability features, backpressure support, load balancing and several Python APIs.
- The R interface is expanded to include Generalized Linear Models
- New machine learning features include eight new transformers, three new estimators (naive Bayes, k-means and isotonic regression) plus three new algorithms (multilayer perceptron classifier, PrefixSpan for sequential pattern mining and FP-Growth for association rule learning)
- Enhancements to existing algorithms include improvements to LDA, decision tree and ensemble features, an improved Pregel API for GraphX plus an ability to distribute matrix inversions for Gaussian Mixture Models (GMM).
- Other new machine learning features include model summaries for linear and logistic regression, a splitting tool to define train and validation samples and a multiclass classification evaluator.
GraphX development has flatlined since the component graduated from Alpha in Spark 1.2.
Mesosphere, Typesafe, Tencent, Palantir, Cloudera, Hortonworks, Huawei, Shopify, Netflix, Intel, Yahoo, Kixer, UC Berkeley and Databricks all participated in release testing. Note that IBM, for all its marketing hoopla, contributes little or nothing to the project.




Leave a comment